How to Survive a ‘Missile Attack’ and the Other Latest Cyberthreats
Robi Singh, mainframe architect at Vertali, offers advice for recovering in time and staying in business, including descriptions of the latest attack methods and how they can be defeated by resilient architecture

What do Jaguar Land Rover, Asahi Breweries, retailers Marks & Spencer and The Co-operative, Kido’s chain of nurseries and numerous airports have in common? They have all been widely known, recent victims of successful cyberattacks—and will not be the last. It’s only a matter of time before a poorly prepared organization will be unable to recover in sufficient time, and will go out of business.
How can you be a cyber survivor? This article explores three key issues: How likely is the threat? How should the IT community respond? And does outsourcing play a negative role in the response?
How Likely Is the Threat?
The threats are real and increasing every day; kids hacking into a nursery database and stealing 8,000 IDs to get £600K in bitcoins makes for easy journalism. The Jaguar attack could have cost the UK 130,000 well-paid jobs and had to be backed by a £1.5 billion fund. Just why the U.K. government had to backstop the inadequate security cover of an Indian conglomerate will be discussed later.
IT management have yet to grasp the extent of the dangers that exist, and people in my profession—databases—have not been bold enough in explaining the risks in the response. Many managers think that because all the data is encrypted in the database and encrypted in transit, there is no risk to their data. This is a fallacy for three reasons.
Harvest Now, Decrypt Later
First, the data can be taken today and decrypted later, when either better decryption is available from AI or faster processors can break the code. A banking customer database that contains the account details of 40 million customers with their regular transactions from six months ago would still be an enormous breach.
Data in CLEAR
Second, the data is not encrypted when the database presents the data to the application. It is decrypted and in CLEAR. Therefore, a simple piece of code that reads John Smith and adds £10 to the account of Jane Smith would be undetected for some time.
‘Missile Attacks’
Third, the more recent development of the so-called “missile attack” involves the aiming to cause as much damage to the data in as short a time as possible. It overwrites or destroys the data files whether they are encrypted or not. Your data is gone.
The Problem With Recovery
Many IT managers do not realize that the cybersecurity team are losing their sleep over the missile scenario, along with the database team who realize how difficult the recovery can be.
The IBM Db2 360 High Availability Reviews (an assessment by IBM on infrastructure and reliability) posed the question: When was the last time you tested or recovered all your Db2 data in mass recovery mode? How can you guarantee that it would work? How long would it take? Most customers failed these questions. Why? The answer is that 10 or 15 years ago, we tested that at least 12 months ago, because the typical disaster recovery was based on three things:
- Full Image Copy (FIC) from overnight
- Db2 logs that were remote copied to DR site or sent offsite
- Db2 Recover that recovered all data from last image copy to latest DB2 log available
This meant that all data was mass-recovered typically every 12 months and the process was tested. Even then, it did not always work cleanly. I remember a couple of times a SEV1 call to the database tool vendors was required and PTF xyz had to be applied in an emergency mode. However, it did not matter if the recovery at the DR site took 12 or 15 hours, so long as it worked. This recovery worked offline to the parallel operation of the live service.
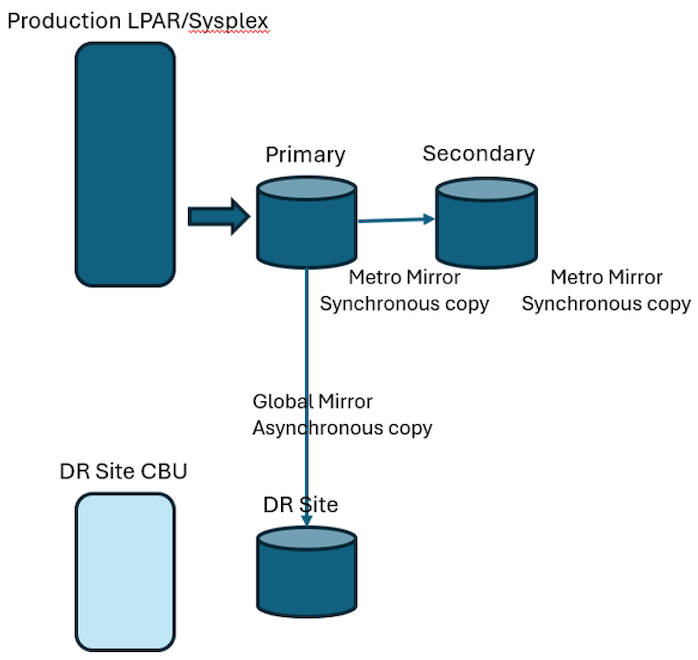
Everything changed when the Bank of England rules directed that a bank had to actually run for several hours at DR site to prove it worked. We could no longer afford the 12 or 15 hours of downtime. ATMs, point-of-sale and internet banking had changed the whole availability model. For others, as well, the improved disk PPRC (peer to peer remote copy) capability meant switching from the old process of FIC plus logs. We all moved to primary and secondary disk. These days, the most common thing is primary copy at main site with secondary copy at second site, with the database solution as active-active at both sites with Metro Mirror (synchronous copy). The DR site is a Global Mirror (asynchronous copy) at least 250km away and only a few milliseconds or less behind.
Many businesses stopped doing the FIC and log-based recovery and have not tested it for years. In the meantime, there has been an explosion of data and data types. It is no longer just numerical and character data. There is XML data, LOBS (large objects), BLOBs (binary large objects) and User Defined Data Types. All these need to be recovered to the same point-in-time potentially.
The reality is that the database teams have no idea how it would work or how long it would take. We don’t know if there are enough devices, IO bandwidth, tape units, CPU power or SORT space to do a mass data recovery. The threat today is not matched by the backup and recovery processes from 10 or 15 years ago.
So, if that covers the scale of the threat and serious issues relating to recovery, what can people do about it?
How Should the IT Community Respond?
The EU’s Digital Operational Resilience Act (DORA) is the new de facto standard for financial entities and their information and communication (ICT) providers. This regulation seeks to strengthen the digital resilience of financial entities. From January 2025 it required banks, insurance companies, investment firms and other financial entities to be able to withstand, respond to, and recover from ICT disruptions such as cyberattacks, system failures or natural disasters.
All entities that participate in payment schemes such as the Single European Payments Area (SEPA), where financial organizations are inter-dependent, must have fully tested recovery processes and procedures in place. The risk to the financial and civil stability of financial markets and countries is great. A significant failure of one organization puts many others at risk.
However, IT management in some organizations has still not grasped that the threats are real. It’s not about meeting regulations to avoid fines—the regulations are playing catch-up in a situation that is evolving, as Jaguar Land Rover demonstrated. An entire company can be wiped out by a successful cyberattack. A bank could not sustain an equivalent outage of 45 days: It would cease trading and lose its banking license in days.
It may take such a serious event and for a company or bank to collapse before some IT managers understand the scale of the problem and the risks they face today.
The Right Recovery Process
Some banks are two to three years down the road with investing in cyberattack recovery plans. Most IT operations I have come across have no plan.
An effective recovery process requires four key elements:
- A periodic and frequent immutable copy of the data
- A process to detect when a breach has happened
- The ability to report to the regulators that a breach has happened
- A predefined and tested recovery plan
The first thing a successful cyberattack would want to do is delete or overwrite the backups of the data. Once that is done, there is no possible data recovery. Any damage to the live production data is permanent at this point. So, the copies of data must be immutable (unable to be changed) and unreachable from the live systems.
Next, these copies must be frequent, and the more frequent, the better and more usable. This is highly dependent on the volatility of the data. A typical Customer Information with name, address, DOB and product holdings in a bank changes <1% daily, whereas a customer account with transactions lists from ATMs, PoS, online transactions and other swipes changes often. The best approach is one where after a base copy of all data is taken, it is incremental and only changed data is copied. This cuts down enormously on the size of the data copy area.
In addition, these data copies must be regularly recovered and analyzed to detect when a data breach has occurred. This is the hardest part; a quick validation of data structure is easy, but validating the structure of each page of data is more difficult and time-consuming. Doing actual application validation is the most difficult part.
Finally, there must be a way of getting the good data back to the live systems so that the data is usable to the DBAs (database administrators) and storage engineers. They must then decide to recover a subset of the data or everything.
A potential solution is shown in the graphic below. View the situation described before as a normal configuration these days. There is a live system with primary and secondary disk as synchronous copy and an asynchronous copy to DR site. The issue some IT managers fail to grasp is that this is all one copy of the data. The IO subsystem can corrupt the data everywhere at the same time.
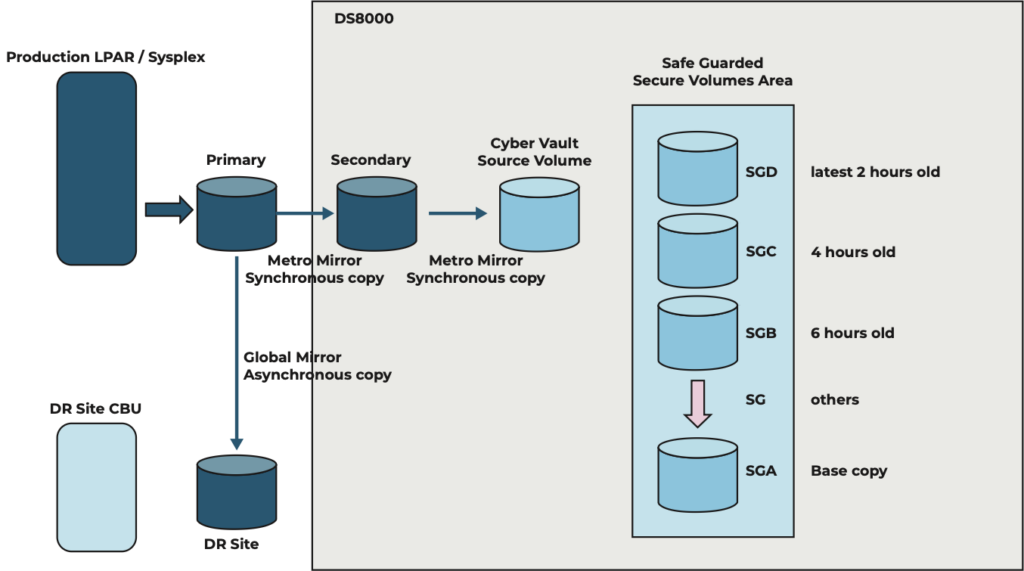
The image below has evolved, a new Metro Mirror has appeared, and there is now an immutable safe guarded (SG) copy taken every two hours. Inside the disk system it monitors which tracks have been updated, and only updated tracks are copied from the last time. A recover would require a base copy SGA + SGothers + SGB + SGC + SGD = recovery point 2 hours ago.
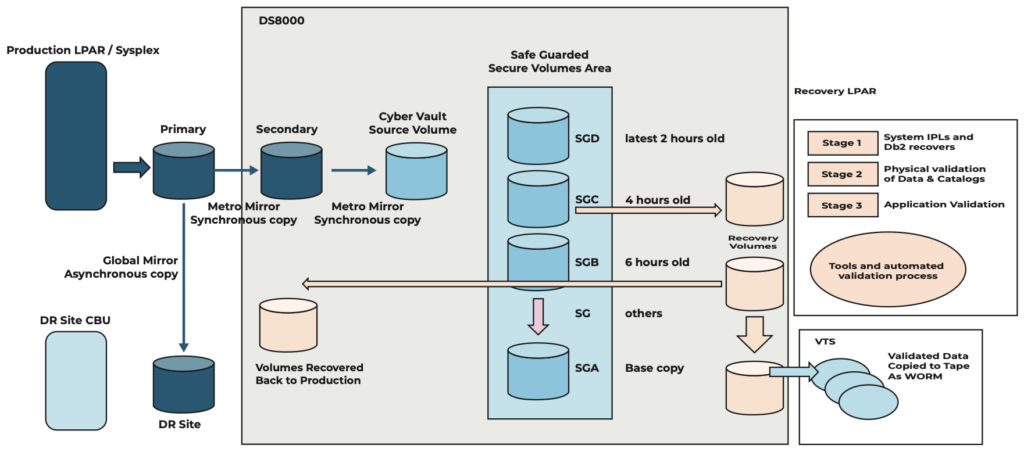
Finally, the other parts arrive, and we see the recovery LPARs and volumes, the validation processes, the ability to copy volumes back to live environment and copy validated data to tape WORM.
The solution being discussed here is IBM Cyber Vault, which makes use of features and facilities available inside the DS8000 storage subsystem.
However, for many organizations, the loss of even two hours or eight hours of data would be disastrous and extremely costly. The upside is that at least the organization would survive.
What should be coming, as announced at this year’s z Resilience conference in Amsterdam, is IBM’s intention to merge Cyber Vault Safeguarded Copy with the Db2 logs in the IBM Db2 RECOVER database utility. As this means that the recovery point can be rolled forward to point-in-time just before the cyberattack, recovery will be possible for single objects or mass recovery. This is the solution to the “missile attack” scenario mentioned earlier.
When Db2 RECOVER is combined with IBM Cyber Vault technology, this amounts to a powerful gear change in speed and capability. It would replace all current backup and recovery processes.
Does Outsourcing Play a Negative Role in the Response?
Yes, it does. At the very least, it can mean the dilution of responsibility. Imagine a scenario where there is a bank, an IT service provider and a separate development area which has two companies supporting different applications. When it comes to cybersecurity, the bank sees it as the responsibility of the IT service provider, and the IT service provider sees it as the responsibility of the bank or the application teams. This is why DORA regulations make it clear it is the joint responsibility of both the bank and the IT service provider.
The under-staffing support model in some IT service providers, moving more support to less qualified resources—combined with a shortage of experienced Z-skilled people in many service providers—means they are reluctant to take on additional work. Service improvements are resisted or overpriced to be out of scope “this year” and then next year. There is also a culture in some IT service providers that IT security and cyberattacks are not the responsibility of the provider, despite the clear statements of regulators that there is a joint responsibility. When I worked for an IT service provider, I attended an internal presentation which clearly stated that DORA regulations do not apply to the provider and only the bank is responsible for compliance. While being completely incorrect, this was also a widely held view.
Being Part of the Solution, Not the Problem
The ability to withstand and recover from a cyberattack is now a business imperative. There is a significant opportunity for service providers to become part of the solution. This is not about satisfying regulators; today, cyber recovery is as essential as disaster recovery and business continuity once were.
The threat of complete business failure due to cyberattack of a critical IT system, by amateur hackers or insiders or state sponsored actors, is real—and it needs a recovery scenario that matches the risk and threat.
IT architects often compare the current security landscape to car insurance uptake. Can you imagine a situation where 80 or 90% of people are driving around without insurance? That is the situation today with IT operations and cyber recovery. For the cost of paying insurance—a tested cyber recovery plan—we risk an enormous bill, a fine and losing the license to drive.
It is the responsibility of the IT manager or IT service provider to get the business to understand that sustaining a successful cyberattack is more likely today than a disaster recovery event. It’s only a matter of time before some organizations will be unable to recover in sufficient time and will go out of business. Given that it can take one or two years to implement an end-to-end solution with backups, recovery to test, detection and live system process for recovery, the time to get started on being a cyber survivor was at least a year ago. But better late than never: if you haven’t already, start now.