Speech-to-Text Conversion Using Python
In this tutorial from Subhasish Sarkar, learn how to build a basic speech-to-text engine using simple Python script
In today’s world, voice technology has become very prevalent. The technology has grown, evolved and matured at a tremendous pace. Starting from voice shopping on Amazon to routine (and growingly complex) tasks performed by the personal voice assistant devices/speakers such as Amazon’s Alexa at the command of our voice, voice technology has found many practical uses in different spheres of life.
Speech-to-Text Conversion
One of the most important and critical functionalities involved with any voice technology implementation is a speech-to-text (STT) engine that performs voice recognition and speech-to-text conversion. We can build a very basic STT engine using a simple Python script. Let’s go through the sequence of steps required.
NOTE: I worked on this proof-of-concept (PoC) project on my local Windows machine and therefore, I assume that all instructions pertaining to this PoC are tried out by the readers on a system running Microsoft Windows OS.
Step 1: Installation of Specific Python Libraries
We will start by installing the Python libraries, namely: speechrecognition, wheel, pipwin and pyaudio. Open your Windows command prompt or any other terminal that you are comfortable using and execute the following commands in sequence, with the next command executed only after the previous one has completed its successful execution.
pip install speechrecognition
pip install wheel
pip install pipwin
pipwin install pyaudioStep 2: Code the Python Script That Implements a Very Basic STT Engine
Let’s name the Python Script file STT.py. Save the file anywhere on your local Windows machine. The Python script code looks like the one referenced below in Figure 1.
Figure 1 Code:
# Python Program that helps translate Speech to Text
import speech_recognition
# The Recognizer is initialized.
UserVoiceRecognizer = speech_recognition.Recognizer()
while(1):
try:
with speech_recognition.Microphone() as UserVoiceInputSource:
UserVoiceRecognizer.adjust_for_ambient_noise(UserVoiceInputSource, duration=0.5)
# The Program listens to the user voice input.
UserVoiceInput = UserVoiceRecognizer.listen(UserVoiceInputSource)
UserVoiceInput_converted_to_Text = UserVoiceRecognizer.recognize_google(UserVoiceInput)
UserVoiceInput_converted_to_Text = UserVoiceInput_converted_to_Text.lower()
print(UserVoiceInput_converted_to_Text)
except KeyboardInterrupt:
print('A KeyboardInterrupt encountered; Terminating the Program !!!')
exit(0)
except speech_recognition.UnknownValueError:
print("No User Voice detected OR unintelligible noises detected OR the recognized audio cannot be matched to text !!!")
Figure 1 Visual:
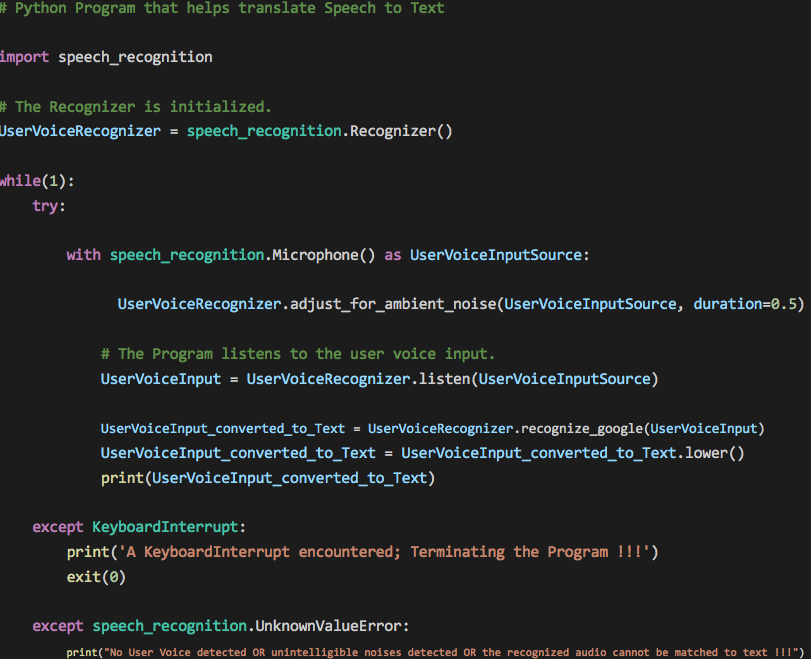
The while loop makes the script run infinitely, waiting to listen to the user voice. A KeyboardInterrupt (pressing CTRL+C on the keyboard) terminates the program gracefully. Your system’s default microphone is used as the source of the user voice input. The code allows for ambient noise adjustment.
Depending on the surrounding noise level, the script can wait for a miniscule amount of time which allows the Recognizer to adjust the energy threshold of the recording of the user voice. To handle ambient noise, we use the adjust_for_ambient_noise() method of the Recognizer class. The adjust_for_ambient_noise() method analyzes the audio source for the time specified as the value of the duration keyword argument (the default value of the argument being one second). So, after the Python script has started executing, you should wait for approximately the time specified as the value of the duration keyword argument for the adjust_for_ambient_noise() method to do its thing, and then try speaking into the microphone.
The SpeechRecognition documentation recommends using a duration no less than 0.5 seconds. In some cases, you may find that durations longer than the default of one second generate better results. The minimum value you need for the duration keyword argument depends on the microphone’s ambient environment. The default duration of one second should be adequate for most applications, though.
The translation of speech to text is accomplished with the aid of Google Speech Recognition (Google Web Speech API), and for it to work, you need an active internet connection.
Step 3: Test the Python Script
The Python script to translate speech to text is ready and it’s now time to see it in action. Open your Windows command prompt or any other terminal that you are comfortable using and CD to the path where you have saved the Python script file. Type in python “STT.py” and press enter. The script starts executing. Speak something and you will see your voice converted to text and printed on the console window. Figure 2 below captures a few of my utterances.
C:UsersUser1Desktop>python "STT.py"
hai
hay
how are you doingFigure 2. A few of the utterances converted to text; the text “hai” corresponds to the actual utterance of “hi,” whereas “hay” corresponds to “hey.”
Figure 3 below shows another instance of script execution wherein user voice was not detected for a certain time interval or that unintelligible noise/audio was detected/recognized which couldn’t be matched/converted to text, resulting in outputting the message “No User Voice detected OR unintelligible noises detected OR the recognized audio cannot be matched to text !!!”
C:UsersUser1Desktop>python "STT.py"
hello
No User Voice detected OR unintelligible noises detected OR the recognized audio cannot be matched to text !!!
No User Voice detected OR unintelligible noises detected OR the recognized audio cannot be matched to text !!!
ok i am doing great
how are you doing
No User Voice detected OR unintelligible noises detected OR the recognized audio cannot be matched to text !!!
No User Voice detected OR unintelligible noises detected OR the recognized audio cannot be matched to text !!!Figure 3. The “No User Voice detected OR unintelligible noises detected OR the recognized audio cannot be matched to text !!!” output message indicates that our STT engine didn’t recognize any user voice for a certain interval of time or that unintelligible noise/audio was detected/recognized which couldn’t be matched/converted to text.
Note: The response from the Google Speech Recognition engine can be quite slow at times.
One thing to note here is, so long as the script executes, your system’s default microphone is constantly in use and the message “Python is using your microphone” depicted in Figure 4 below confirms the fact.

Finally, press CTRL+C on your keyboard to terminate the execution of the Python script. Hitting CTRL+C on the keyboard generates a KeyboardInterrupt exception that has been handled in the first except block in the script which results in a graceful exit of the script. Figure 5 below shows the script’s graceful exit.
C:UsersUser1Desktop>python "STT.py"
hello
No User Voice detected OR unintelligible noises detected OR the recognized audio cannot be matched to text !!!
No User Voice detected OR unintelligible noises detected OR the recognized audio cannot be matched to text !!!
ok i am doing great
how are you doing
No User Voice detected OR unintelligible noises detected OR the recognized audio cannot be matched to text !!!
No User Voice detected OR unintelligible noises detected OR the recognized audio cannot be matched to text !!!
A KeyboardInterrupt encountered; Terminating the Program !!!Figure 5. Pressing CTRL+C on your keyboard results in a graceful exit of the executing Python script.
Note: I noticed that the script fails to work when the VPN is turned on. The VPN had to be turned off for the script to function as expected. Figure 6 below demonstrates the erroring out of the script with the VPN turned on.
C:UsersUser1Desktop>python "STT.py"
Traceback (most recent call last):
File "STT.py", line 25, in <module>
UserVoiceInput_converted_to_Text = UserVoiceRecognizer.recognize_google(UserVoiceInput)
File "C:Python38libsite-packagesspeech_recognition__init__.py", line 840, in recognize_google
response = urlopen(request, timeout=self.operation_timeout)
File "C:Python38liburllibrequest.py", line 222, in urlopen
return opener.open(url, data, timeout)
File "C:Python38liburllibrequest.py", line 525, in open
response = self._open(req, data)
File "C:Python38liburllibrequest.py", line 542, in _open
result = self._call_chain(self.handle_open, protocol, protocol +
File "C:Python38liburllibrequest.py", line 502, in _call_chain
result = func(*args)
File "C:Python38liburllibrequest.py", line 1348, in http_open
return self.do_open(http.client.HTTPConnection, req)
File "C:Python38liburllibrequest.py", line 1323, in do_open
r = h.getresponse()
File "C:Python38libhttpclient.py", line 1322, in getresponse
response.begin()
File "C:Python38libhttpclient.py", line 303, in begin
version, status, reason = self._read_status()
File "C:Python38libhttpclient.py", line 264, in _read_status
line = str(self.fp.readline(_MAXLINE + 1), "iso-8859-1")
File "C:Python38libsocket.py", line 669, in readinto
return self._sock.recv_into(b)
ConnectionResetError: [WinError 10054] An existing connection was forcibly closed by the remote hostFigure 6. The Python script fails to work when the VPN is turned on.
When the VPN is turned on, it seems that the Google Speech Recognition API turns down the request. Anybody able to fix the issue is most welcome to get in touch with me here and share the resolution.